今天的開頭我們先看看下圖昨天的label結果:
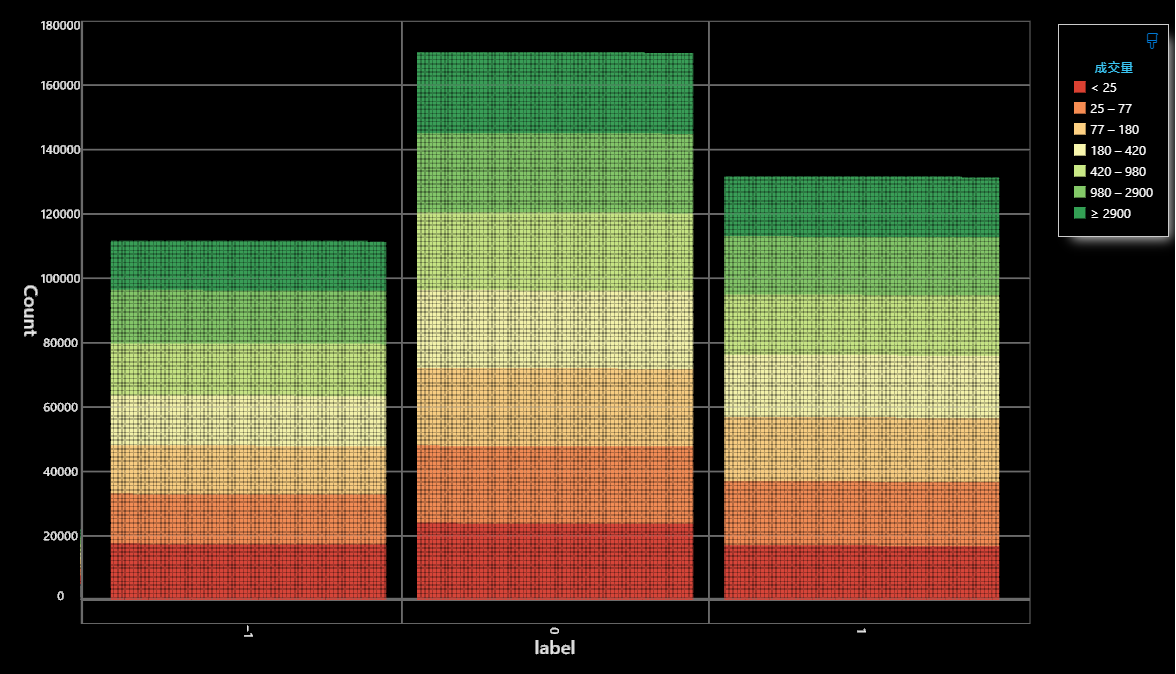
基本上沒有極大的偏向,11:17:13的比例也算是很不錯。
接續下去的話我們就來進行特徵建立吧!
技術指標作為特徵是相對簡單的,並且在實際交易上感覺有用,但是仔細一想就會發現技術指標本身會對於交易資訊有省略的意涵。(沒錯這是一個坑),但是現在我們先用技術指標吧~
技術指標分成幾類,我挑三種來講,根據過去我做的研究也可以靠這三種有不錯的預測績效:
根據我過去研究(如果想看我們可以另外開一集來講),標準差會很大程度上幫助指標運算,震盪指標就挑KD。先以這兩個指標先做,之後想要增加其他的內容我們可以慢慢處理。
先來寫點Code產生技術指標吧!
import talib as ta
import pandas as pd
def calculate_stoch_by_talib(dataframe):
# 使用talib計算STOCH指標
slowk, slowd = ta.STOCH(dataframe['high'], dataframe['low'], dataframe['close'],
fastk_period=5, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0)
# 將結果四捨五入到小數兩位
slowk = round(slowk, 2)
slowd = round(slowd, 2)
return slowk, slowd
# 讀取CSV文件
df = pd.read_csv('label_data.csv')
# 根據股票代號分割資料並計算STOCH指標,然後加入到df中
for stock in df['股票代號'].unique():
stock_data = df[df['股票代號'] == stock]
slowk, slowd = calculate_stoch_by_talib(stock_data)
# 將計算結果加入到原始資料中,並在欄位名稱上標記參數
df.loc[stock_data.index, 'slowk_5_3_3'] = slowk
df.loc[stock_data.index, 'slowd_5_3_3'] = slowd
# 儲存結果到新的CSV文件
df.to_csv('label_data_with_stoch.csv', index=False, encoding='utf_8_sig')
大致上做完就可以改一下準備大量生產不同參數的資料
import talib as ta
import pandas as pd
from itertools import product
def calculate_stoch_by_talib(dataframe, fastk_period, slowk_period, slowd_period):
# 使用talib計算STOCH指標
slowk, slowd = ta.STOCH(dataframe['high'], dataframe['low'], dataframe['close'],
fastk_period=fastk_period,
slowk_period=slowk_period,
slowk_matype=0,
slowd_period=slowd_period,
slowd_matype=0)
# 將結果四捨五入到小數兩位
slowk = round(slowk, 2)
slowd = round(slowd, 2)
return slowk, slowd
# 讀取CSV文件
df = pd.read_csv('label_data.csv')
# 定義參數範圍
fastk_range = range(5, 11)
slowk_period_range = range(3, 6)
slowd_range = range(3, 6)
combinations = product(fastk_range, slowk_period_range, slowd_range)
# 根據股票代號分割資料並計算STOCH指標,然後加入到df中
for fastk, slowk_period, slowd in combinations:
for stock in df['股票代號'].unique():
stock_data = df[df['股票代號'] == stock]
slowk_values, slowd_values = calculate_stoch_by_talib(stock_data, fastk, slowk_period, slowd)
# 根據參數組合調整欄位名稱,並將計算結果加入到原始資料中
df.loc[stock_data.index, f'slowk_{fastk}_{slowk_period}_{slowd}'] = slowk_values
df.loc[stock_data.index, f'slowd_{fastk}_{slowk_period}_{slowd}'] = slowd_values
# 儲存結果到新的CSV文件
df.to_csv('label_data_with_stoch.csv', index=False, encoding='utf_8_sig')
機器學習中雖然理論上越多特徵越容易擬合現實函數,但是也會因為數據過多導致 1. 運算速度變慢 2. 收斂不容易。因此我們會希望採用特徵篩選的方式去挑選我們的特徵。特徵的挑選方式有很多種:
過濾法:
包裝法:
我們可以先採用包裝法(反正我們現在時間多)。會選擇一個有特徵重要性的模型,這時候我們可以選擇基於樹的模型,進行初步的模型訓練之後選擇特徵重要性較高的特徵。這部分有一個坑,如果選擇邏輯回歸等等模型會有共線性的問題。
當有兩個或更多自變數之間存在高度相關(即彼此相關),則稱為「共線性」。共線性可能導致迴歸模型中存在重複的自變數,進而引起模型權重不穩定的問題。
以下是使用決策樹進行的特徵篩選,我們會選取表現最佳的6個參數:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_selection import RFECV
from sklearn.model_selection import StratifiedKFold
# 重新載入數據
data = pd.read_csv('label_data_with_stoch.csv')
# 移除不可使用的欄位
data_cleaned = data.drop(columns=['前10日最高價標準差', '前10日最低價標準差', '最高價+2倍標準差', '最低價-2倍標準差'])
# 移除空值
data_cleaned = data_cleaned.dropna(subset=['label'])
# 分割特徵和目標
X = data_cleaned.drop(columns=['股票代號', '股票名稱', '日期', 'label'])
y = data_cleaned['label']
# 至少要保留幾個特徵
min_features_to_select = 6
# 定義模型
estimator = DecisionTreeClassifier()
# 定義 RFE 與交叉驗證策略
rfecv = RFECV(estimator=estimator, step=1, cv=StratifiedKFold(5),
scoring='accuracy', min_features_to_select=min_features_to_select)
rfecv.fit(X.fillna(0), y)
# 顯示選擇的特徵
selected_features = X.columns[rfecv.support_]
selected_features_list = list(selected_features)
print(selected_features_list)
RFECV(帶有交叉驗證的遞歸特徵消除),是一種特徵篩選方式,其中包含RFE、CV兩部分:
遞歸特徵消除(RFE):
交叉驗證(CV):
RFECV參數的詳細解釋:
特徵篩選完之後我們就可以留下我們的特徵冠軍們。明天我們將一起進行模型建立的步驟,而特徵的結果也會一併在明天公布(畢竟運算KD跟標準差兩種都很消耗資源)


 iThome鐵人賽
iThome鐵人賽